
Benchmark Experiment Host Manager¶
This Python tools helps managing benchmark experiments of Database Management Systems (DBMS) in a Kubernetes-based High-Performance-Computing (HPC) cluster environment. It enables users to configure hardware / software setups for easily repeating tests over varying configurations.
It serves as the orchestrator [2] for distributed parallel benchmarking experiments in a Kubernetes Cloud. This has been tested at Amazon Web Services, Google Cloud, Microsoft Azure, IBM Cloud und Oracle Cloud and at Minikube installations.
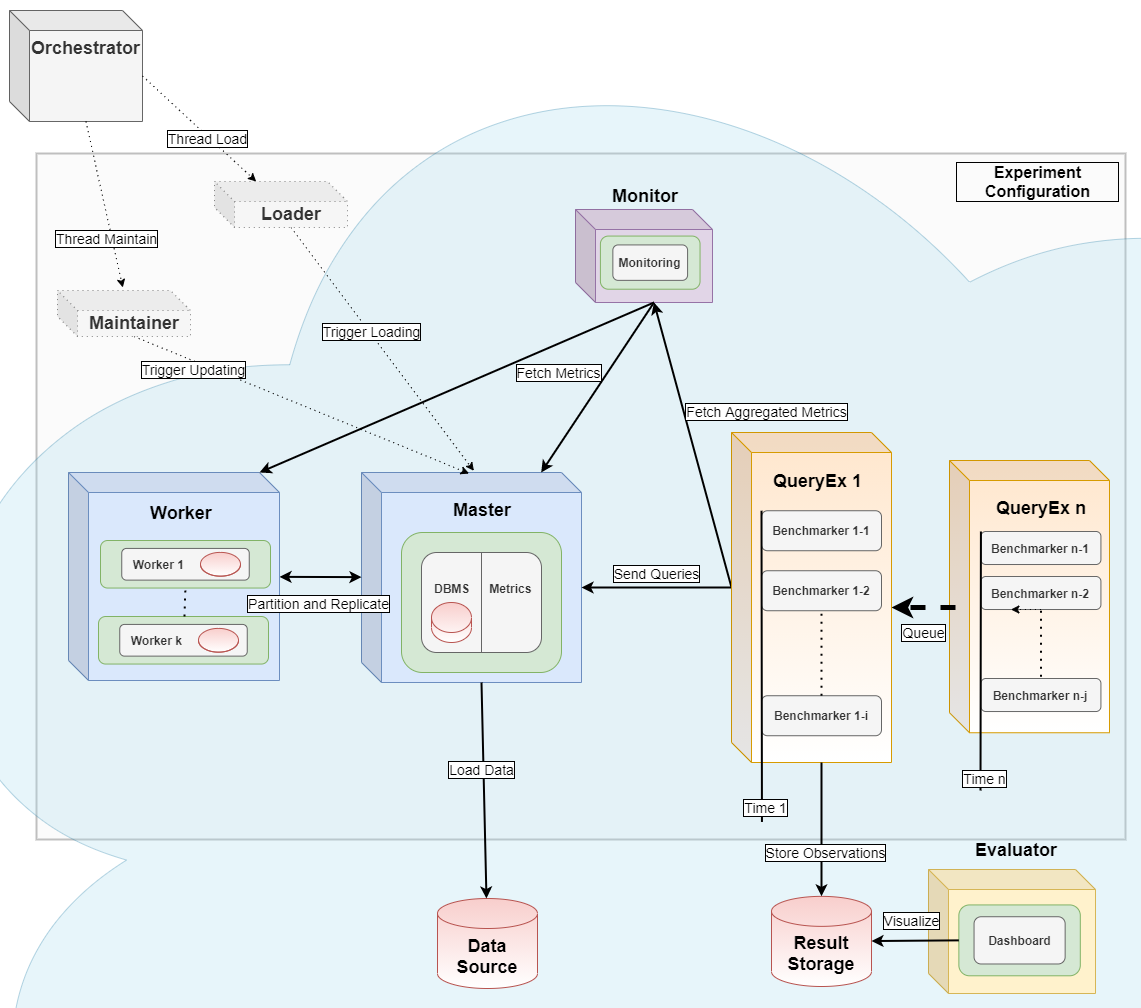
The basic workflow is [1,2]: start a virtual machine, install monitoring software and a database management system, import data, run benchmarks (external tool) and shut down everything with a single command. A more advanced workflow is: Plan a sequence of such experiments, run plan as a batch and join results for comparison.
See the homepage and the documentation.
Installation¶
Download the repository: https://github.com/Beuth-Erdelt/Benchmark-Experiment-Host-Manager
Install the package
pip install bexhomaMake sure you have a working
kubectlinstalled
(Also make sure to have access to a running Kubernetes cluster - for example Minikube)Adjust configuration [tbd in detail]
Rename
k8s-cluster.configtocluster.configSet name of context, namespace and name of cluster in that file
Install data [tbd in detail]
Example for TPC-H SF=1:Run
kubectl create -f k8s/job-data-tpch-1.ymlWhen job is done, clean up with
kubectl delete job -l app=bexhoma -l component=data-sourceand
kubectl delete deployment -l app=bexhoma -l component=data-source.
Install result folder
Runkubectl create -f k8s/pvc-bexhoma-results.yml
Quickstart¶
The repository contains a tool for running TPC-H (reading) queries at MonetDB and PostgreSQL.
Run
tpch run -sf 1 -t 30.You can watch status using
bexperiments statuswhile running.
This is equivalent topython cluster.py status.After benchmarking has finished, run
bexperiments dashboardto connect to a dashboard. You can open dashboard in browser athttp://localhost:8050.
This is equivalent topython cluster.py dashboard
Alternatively you can open a Jupyter notebook athttp://localhost:8888.
More Informations¶
For full power, use this tool as an orchestrator as in [2]. It also starts a monitoring container using Prometheus and a metrics collector container using cAdvisor. It also uses the Python package dbmsbenchmarker as query executor [2] and evaluator [1]. See the images folder for more details.
This module has been tested with Brytlyt, Citus, Clickhouse, DB2, Exasol, Kinetica, MariaDB, MariaDB Columnstore, MemSQL, Mariadb, MonetDB, MySQL, OmniSci, Oracle DB, PostgreSQL, SingleStore, SQL Server and SAP HANA.
References¶
Erdelt P.K. (2021) A Framework for Supporting Repetition and Evaluation in the Process of Cloud-Based DBMS Performance Benchmarking. In: Nambiar R., Poess M. (eds) Performance Evaluation and Benchmarking. TPCTC 2020. Lecture Notes in Computer Science, vol 12752. Springer, Cham. https://doi.org/10.1007/978-3-030-84924-5_6
[2] Orchestrating DBMS Benchmarking in the Cloud with Kubernetes
(old, slightly outdated docs)