API Details
This document contains API details about methods for parameters
:ref:
`set_code()<set-code>`:ref:
`set_experiment()<set-experiment>`:ref:
`set_workload()<set-workload>`:ref:
`set_connectionmanagement()<set-connection-management>`:ref:
`set_querymanagement()<set-query-management>`:ref:
`set_resources()<set-resources>`:ref:
`set_ddl_parameters()<set-ddl-parameters>`
and methods for the workflow
:ref:
`runExperiment()<run-experiment>`:ref:
`prepareExperiment()<prepare-experiment>`:ref:
`startExperiment()<start-experiment>`:ref:
`runBenchmarks()<run-benchmarks>`:ref:
`stopExperiment()<stop-experiment>`:ref:
`cleanExperiment()<clean-experiment>`
Set Code
Sets a code for the collection of experiments. This is used by the benchmarking package https://github.com/Beuth-Erdelt/DBMS-Benchmarker
For a new experiment the code is None.
Set Experiment
cluster.setExperiment(instance, volume, docker, script)
This sets (up to) four central parameter of an experiment
instance: Name of virtual machinevolume: Name of Storage Devicedocker: Name of DBMS docker imagescript: Name of collection of init scripts
The four parameter are given as keys to improve usability, for example script="SF1-indexes" and instance="4000m-16Gi".
Most of these keys are translated into technical details using a configuration file, c.f. an example.
Instances in a Kubernetes cluster are translated using YAML files.
Set Workload
Specify details about the following experiment. This overwrites infos given in the query file.
cluster.set_workload(
name = 'TPC-H Queries',
info = 'This experiment compares instances of different DBMS on different machines.'
)
name: Name of experimentinfo: Arbitrary string
These infos are used in reporting.
Set Connection Management
Specify details about the following experiment. This overwrites infos given in the query file.
cluster.set_connectionmanagement(
numProcesses = 1,
runsPerConnection = 0,
timeout = 600
)
timeout: Maximum lifespan of a connection. Default is None, i.e. no limit.numProcesses: Number of parallel client processes. Default is 1.runsPerConnection: Number of runs performed before connection is closed. Default is None, i.e. no limit.
These values are handed over to the benchmarker.
Set Query Management
Specify details about the following experiment. This overwrites infos given in the query file.
cluster.set_querymanagement(numRun = 1)
numRun: Number of runs each query is run for benchmarking
These values are handed over to the benchmarker, c.f. for more options.
Set Resources
Specify details about the following experiment. This overwrites infos given in the instance description (YAML) in deployments for Kubernetes.
cluster.set_resources(
requests = {
'cpu': '4000m',
'memory': '16Gi'
},
limits = {
'cpu': 0,
'memory': 0
},
nodeSelector = {
'gpu': 'v100',
})
Set DDL Parameters
Specify details about the DDL scripts. This replaces placeholders in the scripts.
cluster.set_ddl_parameters(
shard_count = '2'
)
All occurrences of {shard_count} in the DDL scripts of the following experiment will be replaces by 2.
Run Experiment
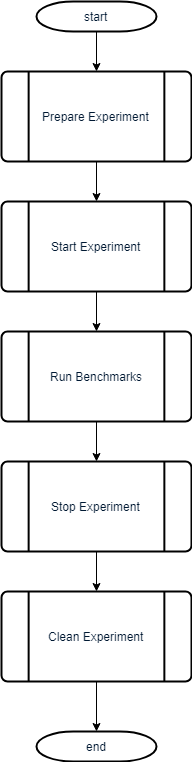
The command cluster.runExperiment() is short for:
cluster.prepareExperiment(instance, volume, docker, script)
cluster.startExperiment()
cluster.runBenchmarks()
cluster.stopExperiment()
cluster.cleanExperiment()
Prepare Experiment
This yields a virtual machine with a fixed IP address and a fixed data folder: /data.
In a k8s cluster, this also starts the DBMS.
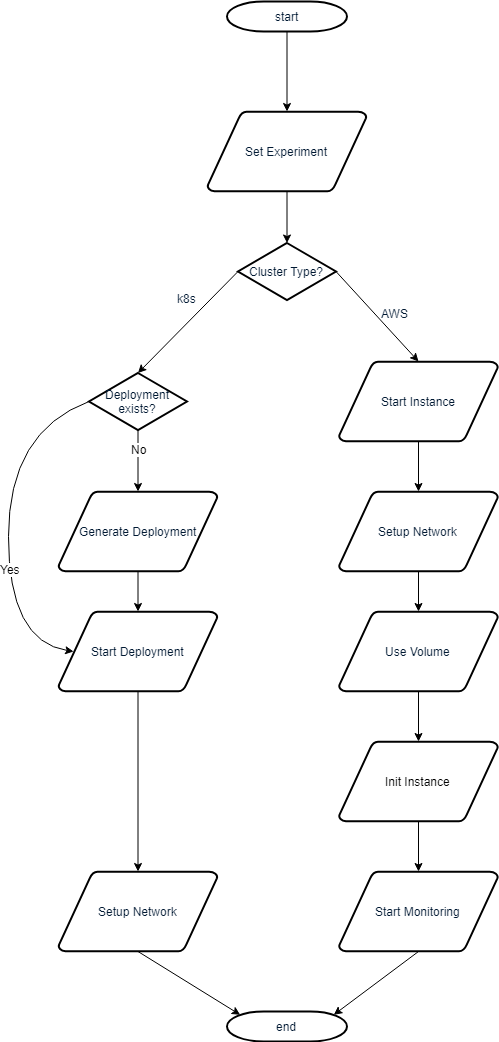
On K8s
The command cluster.prepareExperiment() (basically) is short for:
cluster.setExperiment(instance, volume, docker, script)
cluster.createDeployment()
cluster.startPortforwarding()
cluster.createDeployment(): Creates a deployment (pod and services) of Docker images to k8sSetup Network cluster.startPortforwarding(): Forwards the port of the DBMS in the pod to localhost:fixedport (same for all containers)
See the documentation for more information about deployments.
On AWS
The command cluster.prepareExperiment() (basically) is short for:
cluster.setExperiment(instance, volume, docker, script)
cluster.startInstance()
cluster.attachIP()
cluster.connectSSH()
cluster.attachVolume()
cluster.initInstance()
cluster.startMonitoring()
cluster.mountVolume()
cluster.startInstance(): Starts an instance (AWS EC2 - Virtual Machine)Setup Network
cluster.attachIP(): Attaches a fixed IP (AWS Elastic IP), same for every instancecluster.connectSSH(): Connects to instance via SSHcluster.attachVolume(): Attaches a data volume (AWS EBS)cluster.initInstance(): Logs into necessary services, for example a docker hub (AWS ECR)cluster.startMonitoring(): Starts monitoringcluster.mountVolume(): Mounts the attached volume as/data
Start Experiment
This yields a fully loaded DBMS with a fixed port on the virtual machine in a docker container with the fixed name benchmark (AWS) or a pod with the fixed label app= (k8s) resp.
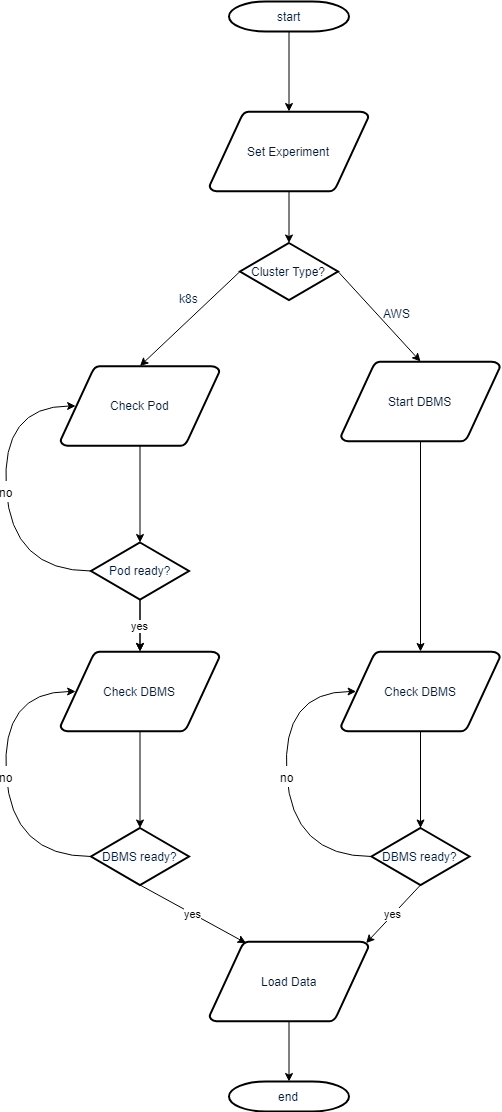
On K8s
The command cluster.startExperiment() (basically) is short for:
cluster.getInfo()
status = cluster.get_pod_status(self.activepod)
while status != "Running":
print(status)
cluster.wait(10)
status = cluster.get_pod_status(self.activepod)
dbmsactive = cluster.check_DBMS_connection(cluster.host, 9091)
while not dbmsactive:
cluster.startPortforwarding()
cluster.wait(10)
dbmsactive = cluster.check_DBMS_connection(cluster.host, 9091)
self.loadData()
cluster.get_pod_status(): Checks status of pod (if pod is running)Setup Network cluster.startPortforwarding(): Forwards the port of the DBMS in the pod to localhost:fixedport (same for all containers)
cluster.check_DBMS_connection(ip, port): Opens a socket to localhost:port to check if dbms is answering
cluster.loadData(): Uploads and runs init scripts to load data to dbms
We check the pod and the network connection again, since the pod may have changed due to restart.
On AWS
The command cluster.startExperiment() (basically) is short for:
cluster.setExperiment(instance, volume, docker, script)
cluster.startDocker()
dbmsactive = cluster.check_DBMS_connection(cluster.host, port)
while not dbmsactive:
cluster.wait(10)
dbmsactive = cluster.check_DBMS_connection(cluster.host, port)
cluster.loadData()
cluster.startDocker(): Starts a docker container of a dbmscluster.check_DBMS_connection(ip, port): Opens a socket to ip:port to check if dbms is answering
cluster.loadData(): Uploads and runs init scripts to load data to dbms
Run Benchmarks
The command cluster.runBenchmarks() runs an external benchmark tool.

Connectionname and Client Configurations
This tool provides the benchmark tool information about the installed experiment host.
This information is packed into a so called connection, which is identified by it’s name.
The default connection name is given as cluster.docker+"-"+cluster.script+"-"+cluster.instance+'-'+cluster.name.
Example: OmniSci-1s-SF10-1xK80-AWS
It is also possible to set an manual name, for example to include a timestamp or more information about the client setting:
connectionname = cluster.getConnectionName()
cluster.runBenchmarks(connection=connectionname+"-2clients")
Simulated clients can optionally be configured via a connection manager:
cluster.set_connectionmanagement(
numProcesses = 2,
runsPerConnection = 0,
timeout = 600)
Workload Configurations
The workload is set in the configuration of the experiment
cluster = testbed(queryfile = queryfile)
The workload can be further manipulated:
cluster.set_workload(
name = 'TPC-H Queries',
info = 'This experiment compares instances of different DBMS on different machines.')
cluster.set_querymanagement(numRun = 64)
Collect Results
For each setup of experiments there is a unique code for identification.
DBMSBenchmarker generates this code when the first experiment is run.
All experiments belonging together will be stored in a folder having this code as name.
It is also possible to continue an experiment by giving cluster.code.
For more information about that, please consult the docs of the benchmark tool: https://github.com/Beuth-Erdelt/DBMS-Benchmarker#connection-file
The result folder also contains
Copies of deployment yaml used to prepare K8s pods
A list of dicts in a file
experiment.config, which lists all experiment steps andCluster information
Host settings: Instances, volumes, init scripts and DBMS docker data
Benchmark settings: Connectionmanagement
and that allow to rerun the experiments.
Note this means it stores confidential informations
Results are inspected best using the dashboard
Collect Host Informations
Some information is given by configuration (JDBC data e.g.), some is collected from the experiment host:
cluster.get_host_memory()
cluster.get_host_cpu()
cluster.get_host_cores()
cluster.get_host_system()
cluster.get_host_diskspace_used()
cluster.get_host_diskspace_used_data()
cluster.get_host_cuda()
cluster.get_host_gpus()
cluster.copyInits()
cluster.copyLog()
cluster.downloadLog()
Most of these run inside the docker container:
cluster.get_host_memory(): Collectsgrep MemTotal /proc/meminfo | awk '{print $2}'and multiplies by 1024cluster.get_host_cpu(): Collectscat /proc/cpuinfo | grep \'model name\' | head -n 1cluster.get_host_cores(): Collectsgrep -c ^processor /proc/cpuinfocluster.get_host_system(): Collectsuname -rcluster.get_host_diskspace_used(): Collectsdf / | awk 'NR == 2{print $3}'cluster.get_host_diskspace_used_data(): Collectsdu datadir | awk 'END{ FS=OFS=\"\t\" }END{print $1}'inside docker container, wheredatadiris set in config of DBMScluster.get_host_cuda(): Collectsnvidia-smi | grep \'CUDA\'cluster.get_host_gpus(): Collects nvidia-smi -L and then aggregates the type using Counter([x[x.find(“:”)+2:x.find(“(“)-1] for x in l if len(x)>0])
cluster.copyInits(): Copy init scripts to benchmark result folder on hostcluster.copyLog(): Copy DBMS logs to benchmark result folder on hostcluster.downloadLog(): Downloads the benchmark result folder from host to local result folder
Reporting
The external tool also does reporting, and it uses the host informations among others.
Reporting can be started by cluster.runReporting().
This generates reports about all experiments that have been stored in the same code.
Stop Experiment
This yields the virtual machine in (almost) the same state as if it was just prepared without restarting it.
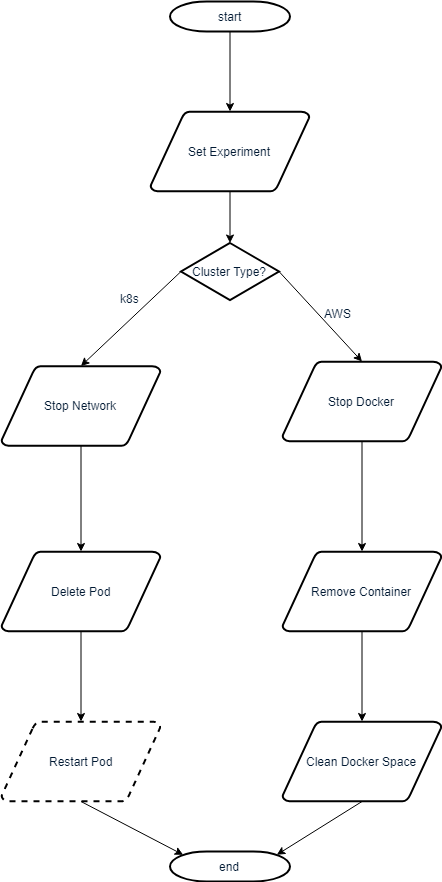
On K8s
The command cluster.stopExperiment() (basically) is short for:
cluster.getInfo()
cluster.stopPortforwarding()
#for p in cluster.pods:
# cluster.delete_pod(p)
cluster.stopPortforwarding(): Disconnects network from current pod``cluster.delete_pod()`: Deletes all pods belonging to namespace / matching label app. Note that the deployment will automatically start a new (clean) pod. Also note that the pod nevertheless will keep data if the storage device has been mounted.</del>`
Note: The pod is not deleted anymore
On AWS
The command cluster.stopExperiment() (basically) is short for:
cluster.connectSSH()
cluster.stopDocker()
cluster.removeDocker()
cluster.cleanDocker()
cluster.stopDocker(): Stops docker container of dbms (docker stop benchmark)cluster.removeDocker(): Removes docker container of dbms (docker rm benchmark)cluster.cleanDocker(): Cleans used space (docker volume rm $(docker volume ls -qf dangling=true))
Clean Experiment
This removes everything from the virtual machine that is related to the experiment (except for results) and shuts it down.
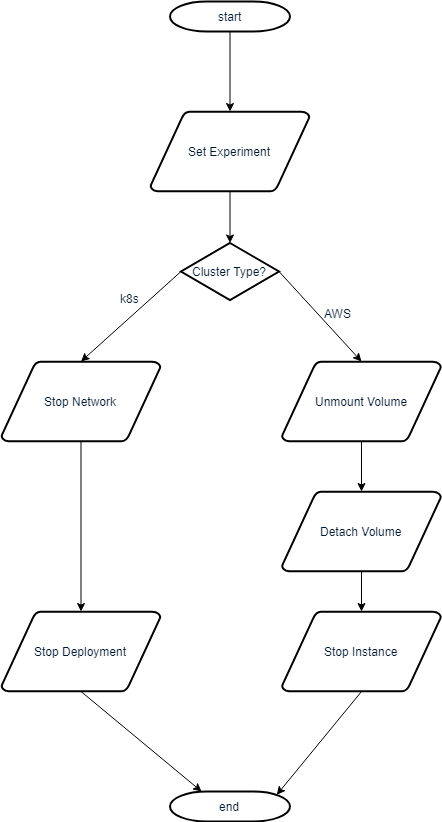
On K8s
The command cluster.cleanExperiment() (basically) is short for:
cluster.stopPortforwarding()
for p in self.pvcs:
self.delete_pvc(p)
for s in cluster.services:
cluster.delete_service(s)
for d in cluster.deployments:
cluster.delete_deployment(d)
for p in cluster.pods:
status = cluster.get_pod_status(cluster.activepod)
while status != "":
print(status)
time.sleep(5)
status = cluster.get_pod_status(cluster.activepod)
cluster.stopPortforwarding(): Kills all processes starting withkubectl port-forwardon the client systemcluster.delete_pvc(): Deletes all PVCs in the current namespace and with fitting label appcluster.delete_service(): Deletes all Services in the current namespace and with fitting label appcluster.delete_deployment(): Deletes all Deployments in the current namespace and with fitting label app
On AWS
The command cluster.cleanExperiment() (basically) is short for:
cluster.unmountVolume()
cluster.detachVolume()
cluster.stopInstance()
cluster.unmountVolume(): Unmounts devicecluster.detachVolume(): Detaches data storage volumecluster.stopInstance(): Stops the instance
Alternative Workflows
Parking DBMS at AWS
An alternative workflow is to not (un)install the DBMS every time they are used, but to park the docker containers:
cluster.setExperiment()
cluster.prepareExperiment()
cluster.unparkExperiment()
cluster.runBenchmarks()
cluster.parkExperiment()
cluster.cleanExperiment()
parkExperiment(): The docker container is stopped and renamed frombechmarktobenchmark-connectionname, whereconnectionnameis the name given for benchmarking.unparkExperiment(): The docker container is renamed frombenchmark-connectionnametobenchmarkand restarted
This allows to keep the prepared docker containers including loaded data.
We can retrieve a list of all parked containers using cluster.listDocker().
To remove all parked containers we can invoke cluster.stopExperiment().
This only works for AWS since in K8s the DBMS is an essential part of the instance (pod).
Rerun a List of Experiments
When we run a workflow using runExperiment() or the composing methods, all steps are logged and stored as a Python dict in the result folder of DBMSBenchmarker.
We may want to rerun the same experiment in all steps.
This needs the cluster config file and the name (code) of the result folder:
workflow = experiments.workflow(clusterconfig='cluster.config', code=code)
workflow.runWorkflow()
workflow.cluster.runReporting()