Benchmark: Benchbase’s TPC-C

Benchbase’s TPC-C [1] implementation [2,5] does not allow scaling data generation and ingestion, but scaling the benchmarking driver. It uses quite some resources, so that for simulating a lot of users, scale-out of the driver is necessary [6].
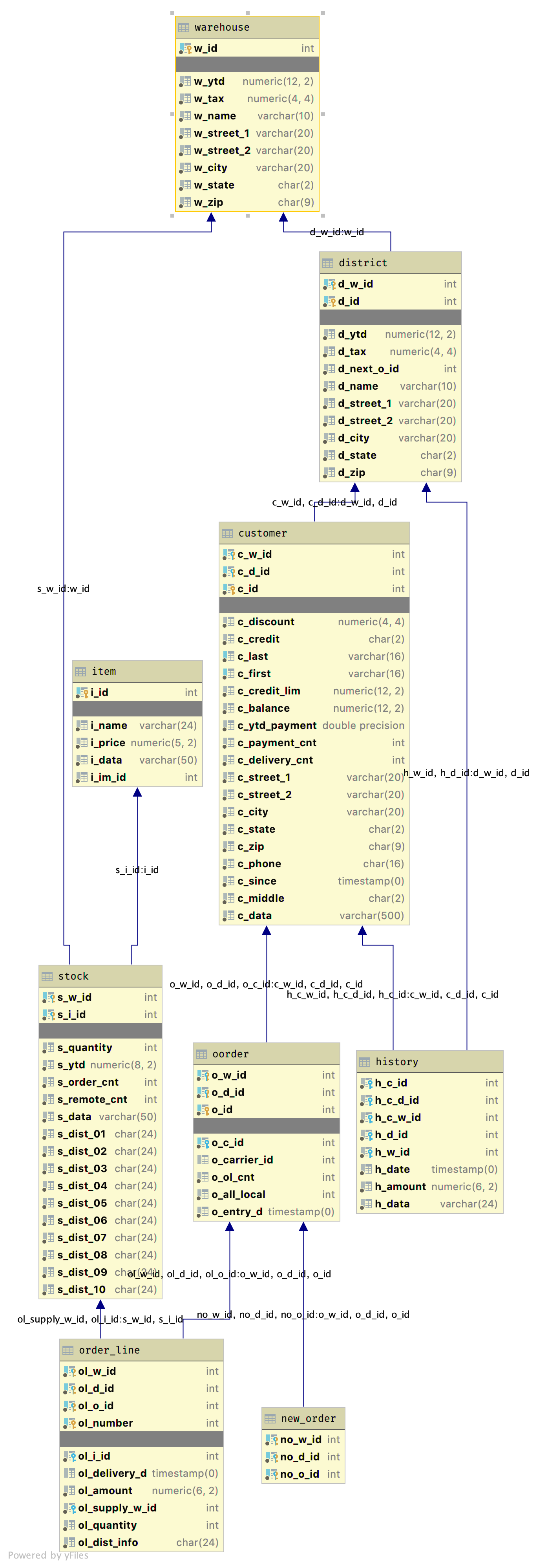
TPC-C involves a mix of five concurrent transactions of different types and complexity either executed on-line or queued for deferred execution. The database is comprised of nine types of tables with a wide range of record and population sizes. TPC-C is measured in transactions per minute (tpmC). While the benchmark portrays the activity of a wholesale supplier, TPC-C is not limited to the activity of any particular business segment, but, rather represents any industry that must manage, sell, or distribute a product or service.
In Benchbase’s implementation, for each warehouse the number of assigned threads is computed [3]. Each thread receives a fixed warehouse and a fixed number of districts and starts a connection [4]. There still can be deadlocks, because A supplying warehouse number (OL_SUPPLY_W_ID) is selected as the home warehouse 99% of the time and as a remote warehouse 1% of the time [1], and a new order sets a lock at the stock table.
The results are not official benchmark results. Exact performance depends on a number of parameters. You may get different results. These examples are solely to illustrate how to use bexhoma and show the result evaluation.
References:
TPC-C Homepage: https://www.tpc.org/tpcc/
Benchbase Repository: https://github.com/cmu-db/benchbase/wiki/TPC-C
Benchbase threads per warehouse: https://github.com/cmu-db/benchbase/blob/main/src/main/java/com/oltpbenchmark/benchmarks/tpcc/TPCCBenchmark.java
Benchbase connect: https://github.com/cmu-db/benchbase/blob/main/src/main/java/com/oltpbenchmark/api/BenchmarkModule.java#L82
OLTP-Bench: An Extensible Testbed for Benchmarking Relational Databases: http://www.vldb.org/pvldb/vol7/p277-difallah.pdf
A Cloud-Native Adoption of Classical DBMS Performance Benchmarks and Tools: https://doi.org/10.1007/978-3-031-68031-1_9
Perform Benchmark
You will have to change the node selectors there (to names of nodes, that exist in your cluster - or to leave out the corresponding parameters):
BEXHOMA_NODE_SUT="cl-worker11"
BEXHOMA_NODE_LOAD="cl-worker19"
BEXHOMA_NODE_BENCHMARK="cl-worker19"
LOG_DIR="./logs_tests"
BEXHOMA_MS=1
BEXHOMA_STORAGE_CLASS="shared"
mkdir -p $LOG_DIR
For performing the experiment we can run the benchbase file.
Example:
bexhoma benchbase \
-dbms PostgreSQL \
-sf 16 \
-xsd 5 \
-xtb 1024 \
-xnbf 16 \
-nbp 1,2 \
-nbt 160 \
-ms $BEXHOMA_MS \
-tr \
-rss 50Gi \
-rnn $BEXHOMA_NODE_SUT -rnl $BEXHOMA_NODE_LOAD -rnb $BEXHOMA_NODE_BENCHMARK \
run &>$LOG_DIR/docs_benchbase_postgresql_scale.log
This
starts a clean instance of PostgreSQL (
-dbms)data directory inside a Docker container
starts 1 loader pod (per DBMS) that
creates TPC-C schema in the database
imports data for 16 (
-sf) warehouses into the DBMSusing all threads of driver machine (benchbase setting)
runs streams of TPC-C queries (per DBMS)
running for 5 (
-xsd) minuteseach stream (pod) having 16 threads to simulate 16 users (
-nbt)-nbp: first stream 1 pod, second stream 2 pods (8 threads each)target is 16x(
-ltf) 1024 (-xtb) ops
with a maximum of 1 DBMS per time (
-ms)tests if results match workflow (
-tr)shows a summary
Status
You can watch the status while benchmark is running via bexhoma status
Dashboard: Running
Cluster Prometheus: Running
Message Queue: Running
Data directory: Running
Result directory: Running
+---------------------+--------------+--------------+----------------+-----------------------------+
| 1726658756 | sut | loaded [s] | use case | benchmarker |
+=====================+==============+==============+================+=============================+
| PostgreSQL-1-1-1024 | (1. Running) | 62 | benchbase_tpcc | (2. Succeeded) (2. Running) |
+---------------------+--------------+--------------+----------------+-----------------------------+
The code 1726658756 is the unique identifier of the experiment.
You can find the number also in the output of benchbase.py.
Cleanup
The script is supposed to clean up and remove everything from the cluster that is related to the experiment after finishing.
If something goes wrong, you can also clean up manually with bexperiment stop (removes everything) or bexperiment stop -e 1726658756 (removes everything that is related to experiment 1726658756).
Evaluate Results
At the end of a benchmark you will see a summary like
docs_benchbase_postgresql_scale.log
## Show Summary
### Workload
Benchbase Workload tpcc SF=16
* Type: benchbase
* Duration: 1164s
* Code: 1783808175
* Benchbase runs a TPC-C experiment.
* This experiment compares run time and resource consumption of Benchbase queries in different DBMS.
* Benchbase data is generated and loaded using several threads.
* Benchmark is 'tpcc'. Scaling factor is 16. Target is based on multiples of '1024'. Factors for benchmarking are [16]. Benchmarking runs for 5 minutes.
* Experiment uses bexhoma version 0.10.4.
* Experiment is limited to DBMS ['PostgreSQL'].
* Import is handled by 1 processes (pods).
* Loading is fixed to cl-worker19.
* Benchmarking is fixed to cl-worker19.
* SUT is fixed to cl-worker36.
* Database uses ephemeral storage of size 50Gi.
* Loading is tested with [1] threads, split into [1] pods.
* Benchmarking is tested with [160] threads, split into [1, 2] pods.
* Benchmarking is run as [1] times the number of benchmarking pods.
* Experiment is run once.
### Connections
* PostgreSQL-1-1-1-1 uses docker image postgres:18.3
* RAM:2164173213696
* CPU:INTEL(R) XEON(R) PLATINUM 8570
* Cores:224
* host:6.8.0-111-generic
* node:cl-worker36
* disk:1079835
* cpu_list:0-223
* args:['-c', 'max_connections=640', '-c', 'max_worker_processes=16', '-c', 'max_parallel_workers=16', '-c', 'max_parallel_workers_per_gather=8', '-c', 'max_parallel_maintenance_workers=4', '-c', 'shared_buffers=16GB', '-c', 'effective_cache_size=40GB', '-c', 'work_mem=512MB', '-c', 'maintenance_work_mem=2GB', '-c', 'autovacuum=off', '-c', 'wal_level=minimal', '-c', 'max_wal_senders=0', '-c', 'max_wal_size=32GB', '-c', 'checkpoint_timeout=1h', '-c', 'checkpoint_completion_target=1.0', '-c', 'lock_timeout=30s', '-c', 'idle_in_transaction_session_timeout=30000']
* requests_cpu:4
* requests_memory:16Gi
* eval_parameters
* code:1783808175
* TENANT_VOL:False
* PostgreSQL-1-1-2-1 uses docker image postgres:18.3
* RAM:2164173213696
* CPU:INTEL(R) XEON(R) PLATINUM 8570
* Cores:224
* host:6.8.0-111-generic
* node:cl-worker36
* disk:1094382
* cpu_list:0-223
* args:['-c', 'max_connections=640', '-c', 'max_worker_processes=16', '-c', 'max_parallel_workers=16', '-c', 'max_parallel_workers_per_gather=8', '-c', 'max_parallel_maintenance_workers=4', '-c', 'shared_buffers=16GB', '-c', 'effective_cache_size=40GB', '-c', 'work_mem=512MB', '-c', 'maintenance_work_mem=2GB', '-c', 'autovacuum=off', '-c', 'wal_level=minimal', '-c', 'max_wal_senders=0', '-c', 'max_wal_size=32GB', '-c', 'checkpoint_timeout=1h', '-c', 'checkpoint_completion_target=1.0', '-c', 'lock_timeout=30s', '-c', 'idle_in_transaction_session_timeout=30000']
* requests_cpu:4
* requests_memory:16Gi
* eval_parameters
* code:1783808175
* TENANT_VOL:False
### SUT Container Restarts
* bexhoma-sut-postgresql-1-1783808175-55487b9966-tfzjt: 0 0
### Workflow
#### Actual
* DBMS PostgreSQL-1 - Experiment 1 Client 1: benchbase (1 pods)
* DBMS PostgreSQL-1 - Experiment 1 Client 2: benchbase (2 pods)
#### Planned
* DBMS PostgreSQL-1 - Experiment 1 Client 1: benchbase (1 pods)
* DBMS PostgreSQL-1 - Experiment 1 Client 2: benchbase (2 pods)
### Loading
#### Per Run
| | experiment_run | SF | time_load | time_preload | time_generate | time_ingest | time_postload | loading_pods | terminals | tenant_id | type_tenants | num_tenants | vol_tenants | Throughput [SF/h] |
|:---------------|-----------------:|------:|------------:|---------------:|----------------:|--------------:|----------------:|---------------:|------------:|:------------|:---------------|--------------:|:--------------|--------------------:|
| PostgreSQL-1-1 | 1 | 16.00 | 200.00 | 1.00 | 0.00 | 87.00 | 112.00 | 1 | 1 | | | 0 | False | 288.00 |
### Execution
#### Per Connection
| DBMS | phase | job | experiment_run | terminals | target | client | benchmark_run | child | tenant_id | time | num_errors | Throughput (requests/second) | Goodput (requests/second) | efficiency | Latency Distribution.95th Percentile Latency (microseconds) | Latency Distribution.Average Latency (microseconds) |
|:---------------------|:-----------------|:-------------------|-----------------:|------------:|---------:|---------:|----------------:|--------:|------------:|-------:|-------------:|-------------------------------:|----------------------------:|-------------:|--------------------------------------------------------------:|------------------------------------------------------:|
| PostgreSQL-1-1-1-1-1 | PostgreSQL-1-1-1 | PostgreSQL-1-1-1-1 | 1 | 160 | 16384 | 1 | 1 | 1 | 0 | 300.00 | 92 | 10269.88 | 10115.29 | 0.00 | 42199.00 | 15566.00 |
| PostgreSQL-1-1-2-1-1 | PostgreSQL-1-1-2 | PostgreSQL-1-1-2-1 | 1 | 80 | 8192 | 2 | 1 | 1 | 0 | 300.00 | 18 | 4122.73 | 4071.95 | 0.00 | 46585.00 | 19395.00 |
| PostgreSQL-1-1-2-1-2 | PostgreSQL-1-1-2 | PostgreSQL-1-1-2-1 | 1 | 80 | 8192 | 2 | 1 | 2 | 0 | 300.00 | 14 | 4123.38 | 4072.97 | 0.00 | 46612.00 | 19392.00 |
#### Per Phase
| DBMS | phase | experiment_run | terminals | target | benchmark_run | pod_count | tenant_id | time | num_errors | Throughput (requests/second) | Goodput (requests/second) | efficiency | Latency Distribution.95th Percentile Latency (microseconds) | Latency Distribution.Average Latency (microseconds) |
|:-----------------|:-----------------|-----------------:|------------:|---------:|----------------:|------------:|------------:|-------:|-------------:|-------------------------------:|----------------------------:|-------------:|--------------------------------------------------------------:|------------------------------------------------------:|
| PostgreSQL-1-1-1 | PostgreSQL-1-1-1 | 1 | 160 | 16384 | 1 | 1 | 0 | 300.00 | 92 | 10269.88 | 10115.29 | 0.00 | 42199.00 | 15566.00 |
| PostgreSQL-1-1-2 | PostgreSQL-1-1-2 | 1 | 160 | 16384 | 1 | 2 | 0 | 300.00 | 32 | 8246.11 | 8144.92 | 0.00 | 46612.00 | 19393.50 |
### Tests
* TEST passed: No SUT container restarts
* TEST passed: Throughput (requests/second) contains no 0 or NaN
* TEST passed: Workflow as planned
We can see that the overall throughput is close to the target and that scaled-out drivers (2 pods with 8 threads each) have similar results as a monolithic driver (1 pod with 16 threads).
To see the summary again you can simply call bexhoma summary -e 1708411664 with the experiment code.
Detailed Evaluation
Results are transformed into pandas DataFrames and can be inspected in detail. See for example
You can connect to an evaluation server in the cluster by bexhoma dashboard.
This forwards ports, so you have
a Jupyter notebook server at http://localhost:8888
You can connect to an evaluation server locally by bexhoma jupyter.
This forwards ports, so you have
a Jupyter notebook server at http://localhost:8888
Adjust Parameters
The script supports
exact repetitions for statistical confidence
variations to scan a large parameters space
combine results for easy evaluation
There are various ways to change parameters.
Manifests
The YAML manifests for the components can be found in https://github.com/Beuth-Erdelt/Benchmark-Experiment-Host-Manager/tree/master/k8s
SQL Scrips
The SQL scripts for pre and post ingestion can be found in https://github.com/Beuth-Erdelt/Benchmark-Experiment-Host-Manager/tree/master/experiments/benchbase
There are per DBMS
initschema-files, that are invoked before loading of datacheckschema-files, that are invoked after loading of data
You can find the output of the files in the result folder.
Dockerfiles
The Dockerfiles for the components can be found in https://github.com/Beuth-Erdelt/Benchmark-Experiment-Host-Manager/tree/master/images/benchbase
Command line
You maybe want to adjust some of the parameters that are set in the file: python benchbase.py -h
usage: benchbase.py [-h] [-aws] [-dbms [{PostgreSQL,MySQL,MariaDB,YugabyteDB,CockroachDB,DatabaseService,Citus} ...]] [-db] [-sl] [-cx CONTEXT] [-e EXPERIMENT] [-m] [-mc] [-ms MAX_SUT] [-nc NUM_CONFIG]
[-ne NUM_QUERY_EXECUTORS] [-nw NUM_WORKER] [-nwr NUM_WORKER_REPLICAS] [-nws NUM_WORKER_SHARDS] [-nlp NUM_LOADING_PODS] [-nlt NUM_LOADING_THREADS] [-nbp NUM_BENCHMARKING_PODS]
[-nbt NUM_BENCHMARKING_THREADS] [-xnbf NUM_BENCHMARKING_TARGET_FACTORS] [-sf SCALING_FACTOR] [-xsd SCALING_DURATION] [-xli SCALING_LOGGING] [-xkey] [-t TIMEOUT] [-rr REQUEST_RAM]
[-rc REQUEST_CPU] [-rct REQUEST_CPU_TYPE] [-rg REQUEST_GPU] [-rgt REQUEST_GPU_TYPE] [-rst {None,,local-hdd,shared}] [-rss REQUEST_STORAGE_SIZE] [-rnn REQUEST_NODE_NAME]
[-rnl REQUEST_NODE_LOADING] [-rnb REQUEST_NODE_BENCHMARKING] [-tr] [-xbt {tpcc,twitter}] [-xtb TARGET_BASE]
{run,start,load}
Perform TPC-C inspired benchmarks based on Benchbase in a Kubernetes cluster. Optionally monitoring is actived. User can also choose some parameters like number of warehouses and request some resources.
positional arguments:
{run,start,load} start sut, also load data or also run the TPC-C queries
options:
-h, --help show this help message and exit
-aws, --aws fix components to node groups at AWS
-dbms [{PostgreSQL,MySQL,MariaDB,YugabyteDB,CockroachDB,DatabaseService,Citus} ...], --dbms [{PostgreSQL,MySQL,MariaDB,YugabyteDB,CockroachDB,DatabaseService,Citus} ...]
DBMS to load the data
-db, --debug dump debug informations
-sl, --skip-loading do not ingest, start benchmarking immediately
-cx CONTEXT, --context CONTEXT
context of Kubernetes (for a multi cluster environment), default is current context
-e EXPERIMENT, --experiment EXPERIMENT
sets experiment code for continuing started experiment
-m, --monitoring activates monitoring for sut
-mc, --monitoring-cluster
activates monitoring for all nodes of cluster
-ms MAX_SUT, --max-sut MAX_SUT
maximum number of parallel DBMS configurations, default is no limit
-nc NUM_CONFIG, --num-config NUM_CONFIG
number of runs per configuration
-ne NUM_QUERY_EXECUTORS, --num-query-executors NUM_QUERY_EXECUTORS
comma separated list of number of parallel clients
-nw NUM_WORKER, --num-worker NUM_WORKER
number of workers (for distributed dbms)
-nwr NUM_WORKER_REPLICAS, --num-worker-replicas NUM_WORKER_REPLICAS
number of workers replications (for distributed dbms)
-nws NUM_WORKER_SHARDS, --num-worker-shards NUM_WORKER_SHARDS
number of worker shards (for distributed dbms)
-nlp NUM_LOADING_PODS, --num-loading-pods NUM_LOADING_PODS
total number of loaders per configuration
-nlt NUM_LOADING_THREADS, --num-loading-threads NUM_LOADING_THREADS
total number of threads per loading process
-nbp NUM_BENCHMARKING_PODS, --num-benchmarking-pods NUM_BENCHMARKING_PODS
comma separated list of number of benchmarkers per configuration
-nbt NUM_BENCHMARKING_THREADS, --num-benchmarking-threads NUM_BENCHMARKING_THREADS
total number of threads per benchmarking process
-xnbf NUM_BENCHMARKING_TARGET_FACTORS, --num-benchmarking-target-factors NUM_BENCHMARKING_TARGET_FACTORS
comma separated list of factors of 16384 ops as target - default range(1,9)
-sf SCALING_FACTOR, --scaling-factor SCALING_FACTOR
scaling factor (SF) = number of warehouses
-xsd SCALING_DURATION, --scaling-duration SCALING_DURATION
scaling factor = duration in minutes
-xli SCALING_LOGGING, --scaling-logging SCALING_LOGGING
logging status every x seconds
-xkey, --extra-keying
activate keying and waiting time
-t TIMEOUT, --timeout TIMEOUT
timeout for a run of a query
-rr REQUEST_RAM, --request-ram REQUEST_RAM
request ram
-rc REQUEST_CPU, --request-cpu REQUEST_CPU
request cpus
-rct REQUEST_CPU_TYPE, --request-cpu-type REQUEST_CPU_TYPE
request node having node label cpu=
-rg REQUEST_GPU, --request-gpu REQUEST_GPU
request number of gpus
-rgt REQUEST_GPU_TYPE, --request-gpu-type REQUEST_GPU_TYPE
request node having node label gpu=
-rst {None,,local-hdd,shared}, --request-storage-type {None,,local-hdd,shared}
request persistent storage of certain type
-rss REQUEST_STORAGE_SIZE, --request-storage-size REQUEST_STORAGE_SIZE
request persistent storage of certain size
-rnn REQUEST_NODE_NAME, --request-node-name REQUEST_NODE_NAME
request a specific node
-rnl REQUEST_NODE_LOADING, --request-node-loading REQUEST_NODE_LOADING
request a specific node
-rnb REQUEST_NODE_BENCHMARKING, --request-node-benchmarking REQUEST_NODE_BENCHMARKING
request a specific node
-tr, --test-result test if result fulfills some basic requirements
-xbt {tpcc,twitter}, --benchmark {tpcc,twitter}
type of benchmark
-xtb TARGET_BASE, --target-base TARGET_BASE
ops as target, base for factors - default 1024 = 2**10
Monitoring
Monitoring can be activated for DBMS only (-m) or for all components (-mc).
Example:
bexhoma benchbase \
-dbms PostgreSQL \
-sf 16 \
-xsd 5 \
-xtb 1024 \
-xnbf 16 \
-nbp 1,2 \
-nbt 160 \
-m \
-mc \
-ms $BEXHOMA_MS \
-tr \
-rss 50Gi \
-rnn $BEXHOMA_NODE_SUT -rnl $BEXHOMA_NODE_LOAD -rnb $BEXHOMA_NODE_BENCHMARK \
run &>$LOG_DIR/docs_benchbase_postgresql_monitoring.log
The result looks something like
docs_benchbase_postgresql_monitoring.log
## Show Summary
### Workload
Benchbase Workload tpcc SF=16
* Type: benchbase
* Duration: 1195s
* Code: 1783809346
* Benchbase runs a TPC-C experiment.
* This experiment compares run time and resource consumption of Benchbase queries in different DBMS.
* Benchbase data is generated and loaded using several threads.
* Benchmark is 'tpcc'. Scaling factor is 16. Target is based on multiples of '1024'. Factors for benchmarking are [16]. Benchmarking runs for 5 minutes.
* Experiment uses bexhoma version 0.10.4.
* System metrics are monitored by a cluster-wide installation.
* Experiment is limited to DBMS ['PostgreSQL'].
* Import is handled by 1 processes (pods).
* Loading is fixed to cl-worker19.
* Benchmarking is fixed to cl-worker19.
* SUT is fixed to cl-worker36.
* Database uses ephemeral storage of size 50Gi.
* Loading is tested with [1] threads, split into [1] pods.
* Benchmarking is tested with [160] threads, split into [1, 2] pods.
* Benchmarking is run as [1] times the number of benchmarking pods.
* Experiment is run once.
### Connections
* PostgreSQL-1-1-1-1 uses docker image postgres:18.3
* RAM:2164173213696
* CPU:INTEL(R) XEON(R) PLATINUM 8570
* Cores:224
* host:6.8.0-111-generic
* node:cl-worker36
* disk:1067056
* cpu_list:0-223
* args:['-c', 'max_connections=640', '-c', 'max_worker_processes=16', '-c', 'max_parallel_workers=16', '-c', 'max_parallel_workers_per_gather=8', '-c', 'max_parallel_maintenance_workers=4', '-c', 'shared_buffers=16GB', '-c', 'effective_cache_size=40GB', '-c', 'work_mem=512MB', '-c', 'maintenance_work_mem=2GB', '-c', 'autovacuum=off', '-c', 'wal_level=minimal', '-c', 'max_wal_senders=0', '-c', 'max_wal_size=32GB', '-c', 'checkpoint_timeout=1h', '-c', 'checkpoint_completion_target=1.0', '-c', 'lock_timeout=30s', '-c', 'idle_in_transaction_session_timeout=30000']
* requests_cpu:4
* requests_memory:16Gi
* eval_parameters
* code:1783809346
* TENANT_VOL:False
* PostgreSQL-1-1-2-1 uses docker image postgres:18.3
* RAM:2164173213696
* CPU:INTEL(R) XEON(R) PLATINUM 8570
* Cores:224
* host:6.8.0-111-generic
* node:cl-worker36
* disk:1095685
* cpu_list:0-223
* args:['-c', 'max_connections=640', '-c', 'max_worker_processes=16', '-c', 'max_parallel_workers=16', '-c', 'max_parallel_workers_per_gather=8', '-c', 'max_parallel_maintenance_workers=4', '-c', 'shared_buffers=16GB', '-c', 'effective_cache_size=40GB', '-c', 'work_mem=512MB', '-c', 'maintenance_work_mem=2GB', '-c', 'autovacuum=off', '-c', 'wal_level=minimal', '-c', 'max_wal_senders=0', '-c', 'max_wal_size=32GB', '-c', 'checkpoint_timeout=1h', '-c', 'checkpoint_completion_target=1.0', '-c', 'lock_timeout=30s', '-c', 'idle_in_transaction_session_timeout=30000']
* requests_cpu:4
* requests_memory:16Gi
* eval_parameters
* code:1783809346
* TENANT_VOL:False
### SUT Container Restarts
* bexhoma-sut-postgresql-1-1783809346-b69944f99-4qf77: 0 0
### Workflow
#### Actual
* DBMS PostgreSQL-1 - Experiment 1 Client 1: benchbase (1 pods)
* DBMS PostgreSQL-1 - Experiment 1 Client 2: benchbase (2 pods)
#### Planned
* DBMS PostgreSQL-1 - Experiment 1 Client 1: benchbase (1 pods)
* DBMS PostgreSQL-1 - Experiment 1 Client 2: benchbase (2 pods)
### Loading
#### Per Run
| | experiment_run | SF | time_load | time_preload | time_generate | time_ingest | time_postload | loading_pods | terminals | tenant_id | type_tenants | num_tenants | vol_tenants | Throughput [SF/h] |
|:---------------|-----------------:|------:|------------:|---------------:|----------------:|--------------:|----------------:|---------------:|------------:|:------------|:---------------|--------------:|:--------------|--------------------:|
| PostgreSQL-1-1 | 1 | 16.00 | 330.00 | 1.00 | 0.00 | 154.00 | 175.00 | 1 | 1 | | | 0 | False | 174.55 |
### Execution
#### Per Connection
| DBMS | phase | job | experiment_run | terminals | target | client | benchmark_run | child | tenant_id | time | num_errors | Throughput (requests/second) | Goodput (requests/second) | efficiency | Latency Distribution.95th Percentile Latency (microseconds) | Latency Distribution.Average Latency (microseconds) |
|:---------------------|:-----------------|:-------------------|-----------------:|------------:|---------:|---------:|----------------:|--------:|------------:|-------:|-------------:|-------------------------------:|----------------------------:|-------------:|--------------------------------------------------------------:|------------------------------------------------------:|
| PostgreSQL-1-1-1-1-1 | PostgreSQL-1-1-1 | PostgreSQL-1-1-1-1 | 1 | 160 | 16384 | 1 | 1 | 1 | 0 | 300.00 | 95 | 9356.86 | 9217.13 | 0.00 | 46891.00 | 17086.00 |
| PostgreSQL-1-1-2-1-1 | PostgreSQL-1-1-2 | PostgreSQL-1-1-2-1 | 1 | 80 | 8192 | 2 | 1 | 1 | 0 | 300.00 | 20 | 4042.33 | 3989.60 | 0.00 | 50029.00 | 19778.00 |
| PostgreSQL-1-1-2-1-2 | PostgreSQL-1-1-2 | PostgreSQL-1-1-2-1 | 1 | 80 | 8192 | 2 | 1 | 2 | 0 | 300.00 | 28 | 4307.72 | 4250.32 | 0.00 | 49643.00 | 18563.00 |
#### Per Phase
| DBMS | phase | experiment_run | terminals | target | benchmark_run | pod_count | tenant_id | time | num_errors | Throughput (requests/second) | Goodput (requests/second) | efficiency | Latency Distribution.95th Percentile Latency (microseconds) | Latency Distribution.Average Latency (microseconds) |
|:-----------------|:-----------------|-----------------:|------------:|---------:|----------------:|------------:|------------:|-------:|-------------:|-------------------------------:|----------------------------:|-------------:|--------------------------------------------------------------:|------------------------------------------------------:|
| PostgreSQL-1-1-1 | PostgreSQL-1-1-1 | 1 | 160 | 16384 | 1 | 1 | 0 | 300.00 | 95 | 9356.86 | 9217.13 | 0.00 | 46891.00 | 17086.00 |
| PostgreSQL-1-1-2 | PostgreSQL-1-1-2 | 1 | 160 | 16384 | 1 | 2 | 0 | 300.00 | 48 | 8350.05 | 8239.92 | 0.00 | 50029.00 | 19170.50 |
### Monitoring
### Loading phase: SUT deployment
| DBMS | CPU [CPUs] | Max CPU | Max RAM [Gb] | Max RAM Cached [Gb] |
|:-------------------|-------------:|----------:|---------------:|----------------------:|
| PostgreSQL-1-1-1-1 | 108.52 | 2.35 | 1.89 | 3.21 |
| PostgreSQL-1-1-2-1 | 108.52 | 2.35 | 1.89 | 3.21 |
### Loading phase: component loader
| DBMS | CPU [CPUs] | Max CPU | Max RAM [Gb] | Max RAM Cached [Gb] |
|:-------------------|-------------:|----------:|---------------:|----------------------:|
| PostgreSQL-1-1-1-1 | 1982.28 | 15.52 | 0.26 | 0.26 |
| PostgreSQL-1-1-2-1 | 1982.28 | 15.52 | 0.26 | 0.26 |
### Execution phase: SUT deployment
| DBMS | CPU [CPUs] | Max CPU | Max RAM [Gb] | Max RAM Cached [Gb] |
|:-------------------|-------------:|----------:|---------------:|----------------------:|
| PostgreSQL-1-1-1-1 | 3439.76 | 14.10 | 6.40 | 10.52 |
| PostgreSQL-1-1-2-1 | 3896.09 | 14.61 | 9.56 | 16.00 |
### Execution phase: component benchmarker
| DBMS | CPU [CPUs] | Max CPU | Max RAM [Gb] | Max RAM Cached [Gb] |
|:-------------------|-------------:|----------:|---------------:|----------------------:|
| PostgreSQL-1-1-1-1 | 4277.27 | 19.36 | 1.36 | 1.36 |
| PostgreSQL-1-1-2-1 | 4277.27 | 30.53 | 1.36 | 1.36 |
### Tests
* TEST passed: No SUT container restarts
* TEST passed: Loading phase: SUT deployment contains no 0 or NaN in CPU [CPUs]
* TEST passed: Loading phase: component loader contains no 0 or NaN in CPU [CPUs]
* TEST passed: Execution phase: SUT deployment contains no 0 or NaN in CPU [CPUs]
* TEST passed: Execution phase: component benchmarker contains no 0 or NaN in CPU [CPUs]
* TEST passed: Throughput (requests/second) contains no 0 or NaN
* TEST passed: Workflow as planned
This gives a survey about CPU (in CPU seconds) and RAM usage (in Gb) during loading and execution of the benchmark.
In this example, metrics are very instable. Metrics are fetched every 30 seconds. This is too coarse for such a quick example.
Use Persistent Storage
The default behaviour of bexhoma is that the database is stored inside the ephemeral storage of the Docker container. If your cluster allows dynamic provisioning of volumes, you might request a persistent storage of a certain type (storageClass) and size.
Example:
bexhoma benchbase \
-dbms PostgreSQL \
-sf 16 \
-xsd 5 \
-xtb 1024 \
-xnbf 16 \
-nc 2 \
-nbp 1 \
-nbt 160 \
-ms $BEXHOMA_MS \
-tr \
-rsr \
-rss 50Gi \
-rst $BEXHOMA_STORAGE_CLASS \
-rnn $BEXHOMA_NODE_SUT -rnl $BEXHOMA_NODE_LOAD -rnb $BEXHOMA_NODE_BENCHMARK \
run &>$LOG_DIR/docs_benchbase_postgresql_storage.log
The following status shows we have two volumes of type shared.
Every PostgreSQL experiment running Benchbase’s TPC-C of SF=16 (warehouses) will take the databases from these volumes and skip loading.
In this example -nc is set to two, that is the complete experiment is repeated twice for statistical confidence.
The first instance of PostgreSQL mounts the volume and generates the data.
All other instances just use the database without generating and loading data.
+----------------------------------------------+-----------------+-------------------+--------------+-------------------+-----------------+----------------------+-----------+----------+--------+--------+
| Volumes | configuration | experiment | loaded [s] | timeLoading [s] | dbms | storage_class_name | storage | status | size | used |
+==============================================+=================+===================+==============+===================+=================+======================+===========+==========+========+========+
| bexhoma-storage-postgresql-benchbase-tpcc-16 | postgresql | benchbase-tpcc-16 | True | 184 | PostgreSQL | shared | 50Gi | Bound | 50G | 4.8G |
+----------------------------------------------+-----------------+-------------------+--------------+-------------------+-----------------+----------------------+-----------+----------+--------+--------+
The result looks something like
docs_benchbase_postgresql_storage.log
## Show Summary
### Workload
Benchbase Workload tpcc SF=16
* Type: benchbase
* Duration: 1722s
* Code: 1783810567
* Benchbase runs a TPC-C experiment.
* This experiment compares run time and resource consumption of Benchbase queries in different DBMS.
* Benchbase data is generated and loaded using several threads.
* Benchmark is 'tpcc'. Scaling factor is 16. Target is based on multiples of '1024'. Factors for benchmarking are [16]. Benchmarking runs for 5 minutes.
* Experiment uses bexhoma version 0.10.4.
* Experiment is limited to DBMS ['PostgreSQL'].
* Import is handled by 1 processes (pods).
* Loading is fixed to cl-worker19.
* Benchmarking is fixed to cl-worker19.
* SUT is fixed to cl-worker36.
* Database is persisted to disk of type shared and size 50Gi. Persistent storage is removed at experiment start.
* Loading is tested with [1] threads, split into [1] pods.
* Benchmarking is tested with [160] threads, split into [1] pods.
* Benchmarking is run as [1] times the number of benchmarking pods.
* Experiment is run 2 times.
### Connections
* PostgreSQL-1-1-1-1 uses docker image postgres:18.3
* RAM:2164173213696
* CPU:INTEL(R) XEON(R) PLATINUM 8570
* Cores:224
* host:6.8.0-111-generic
* node:cl-worker36
* disk:1062778
* volume_size:50G
* volume_used:4.3G
* cpu_list:0-223
* args:['-c', 'max_connections=640', '-c', 'max_worker_processes=16', '-c', 'max_parallel_workers=16', '-c', 'max_parallel_workers_per_gather=8', '-c', 'max_parallel_maintenance_workers=4', '-c', 'shared_buffers=16GB', '-c', 'effective_cache_size=40GB', '-c', 'work_mem=512MB', '-c', 'maintenance_work_mem=2GB', '-c', 'autovacuum=off', '-c', 'wal_level=minimal', '-c', 'max_wal_senders=0', '-c', 'max_wal_size=32GB', '-c', 'checkpoint_timeout=1h', '-c', 'checkpoint_completion_target=1.0', '-c', 'lock_timeout=30s', '-c', 'idle_in_transaction_session_timeout=30000']
* requests_cpu:4
* requests_memory:16Gi
* eval_parameters
* code:1783810567
* TENANT_VOL:False
* PostgreSQL-1-2-1-1 uses docker image postgres:18.3
* RAM:2164173213696
* CPU:INTEL(R) XEON(R) PLATINUM 8570
* Cores:224
* host:6.8.0-111-generic
* node:cl-worker36
* disk:1062795
* volume_size:50G
* volume_used:4.8G
* cpu_list:0-223
* args:['-c', 'max_connections=640', '-c', 'max_worker_processes=16', '-c', 'max_parallel_workers=16', '-c', 'max_parallel_workers_per_gather=8', '-c', 'max_parallel_maintenance_workers=4', '-c', 'shared_buffers=16GB', '-c', 'effective_cache_size=40GB', '-c', 'work_mem=512MB', '-c', 'maintenance_work_mem=2GB', '-c', 'autovacuum=off', '-c', 'wal_level=minimal', '-c', 'max_wal_senders=0', '-c', 'max_wal_size=32GB', '-c', 'checkpoint_timeout=1h', '-c', 'checkpoint_completion_target=1.0', '-c', 'lock_timeout=30s', '-c', 'idle_in_transaction_session_timeout=30000']
* requests_cpu:4
* requests_memory:16Gi
* eval_parameters
* code:1783810567
* TENANT_VOL:False
### SUT Container Restarts
* bexhoma-sut-postgresql-1-1783810567-f7b89c5b8-xtk95: 0 0
### Workflow
#### Actual
* DBMS PostgreSQL-1 - Experiment 1 Client 1: benchbase (1 pods)
* DBMS PostgreSQL-1 - Experiment 2 Client 1: benchbase (1 pods)
#### Planned
* DBMS PostgreSQL-1 - Experiment 1 Client 1: benchbase (1 pods)
* DBMS PostgreSQL-1 - Experiment 2 Client 1: benchbase (1 pods)
### Loading
#### Per Run
| | experiment_run | SF | time_load | time_preload | time_generate | time_ingest | time_postload | loading_pods | terminals | tenant_id | type_tenants | num_tenants | vol_tenants | Throughput [SF/h] |
|:---------------|-----------------:|------:|------------:|---------------:|----------------:|--------------:|----------------:|---------------:|------------:|:------------|:---------------|--------------:|:--------------|--------------------:|
| PostgreSQL-1-1 | 1 | 16.00 | 781.00 | 1.00 | 0.00 | 364.00 | 416.00 | 1 | 1 | | | 0 | False | 73.75 |
| PostgreSQL-1-2 | 2 | 16.00 | 781.00 | 1.00 | 0.00 | 364.00 | 416.00 | 1 | 1 | | | 0 | False | 73.75 |
### Execution
#### Per Connection
| DBMS | phase | job | experiment_run | terminals | target | client | benchmark_run | child | tenant_id | time | num_errors | Throughput (requests/second) | Goodput (requests/second) | efficiency | Latency Distribution.95th Percentile Latency (microseconds) | Latency Distribution.Average Latency (microseconds) |
|:---------------------|:-----------------|:-------------------|-----------------:|------------:|---------:|---------:|----------------:|--------:|------------:|-------:|-------------:|-------------------------------:|----------------------------:|-------------:|--------------------------------------------------------------:|------------------------------------------------------:|
| PostgreSQL-1-1-1-1-1 | PostgreSQL-1-1-1 | PostgreSQL-1-1-1-1 | 1 | 160 | 16384 | 1 | 1 | 1 | 0 | 300.00 | 1 | 1242.14 | 1232.42 | 0.00 | 526828.00 | 128717.00 |
| PostgreSQL-1-2-1-1-1 | PostgreSQL-1-2-1 | PostgreSQL-1-2-1-1 | 2 | 160 | 16384 | 1 | 1 | 1 | 0 | 300.00 | 0 | 667.37 | 662.88 | 0.00 | 887214.00 | 239475.00 |
#### Per Phase
| DBMS | phase | experiment_run | terminals | target | benchmark_run | pod_count | tenant_id | time | num_errors | Throughput (requests/second) | Goodput (requests/second) | efficiency | Latency Distribution.95th Percentile Latency (microseconds) | Latency Distribution.Average Latency (microseconds) |
|:-----------------|:-----------------|-----------------:|------------:|---------:|----------------:|------------:|------------:|-------:|-------------:|-------------------------------:|----------------------------:|-------------:|--------------------------------------------------------------:|------------------------------------------------------:|
| PostgreSQL-1-1-1 | PostgreSQL-1-1-1 | 1 | 160 | 16384 | 1 | 1 | 0 | 300.00 | 1 | 1242.14 | 1232.42 | 0.00 | 526828.00 | 128717.00 |
| PostgreSQL-1-2-1 | PostgreSQL-1-2-1 | 2 | 160 | 16384 | 1 | 1 | 0 | 300.00 | 0 | 667.37 | 662.88 | 0.00 | 887214.00 | 239475.00 |
### Tests
* TEST passed: No SUT container restarts
* TEST passed: Throughput (requests/second) contains no 0 or NaN
* TEST passed: Workflow as planned
The loading times for both instances of loading are the same, since both relate to the same process of ingesting into the database.
Note the added section about volume_size and volume_used in the connections section.
Also note the size increases from first to second run (benchmark writes data).
Keying and Thinking Time
We can activate waiting times before and after execution of transactions with -xkey to follow TPC-C specifications more closely.
Also also make sure, the number of driver threads (-nbt) is 10 times the number of warehouses (-sf).
Since -nbt can exceed the DBMS’s connection limit at the largest pod count in the -nbp sweep, raise
max_connections accordingly with --set.
bexhoma benchbase \
-dbms PostgreSQL \
-sf 160 \
-xsd 30 \
-xtb 1024 \
-xnbf 1 \
-nc 1 \
-ne 1 \
-nbp 1,2,5,10 \
-nbt 1600 \
-xkey \
-m \
-mc \
-ms $BEXHOMA_MS \
-tr \
-lr 128Gi \
-rr 128Gi \
-rsr \
-rss 100Gi \
-rst $BEXHOMA_STORAGE_CLASS \
-rnn $BEXHOMA_NODE_SUT -rnl $BEXHOMA_NODE_LOAD -rnb $BEXHOMA_NODE_BENCHMARK \
--set deployment[bexhoma-deployment-postgres].container[dbms].max_connections=2000 \
run &>$LOG_DIR/docs_benchbase_postgresql_keytime.log
Evaluate Results
docs_benchbase_postgresql_keytime.log
## Show Summary
### Workload
Benchbase Workload tpcc SF=160
* Type: benchbase
* Duration: 10977s
* Code: 1783812297
* Benchbase runs a TPC-C experiment.
* This experiment compares run time and resource consumption of Benchbase queries in different DBMS.
* Benchbase data is generated and loaded using several threads.
* Benchmark is 'tpcc'. Scaling factor is 160. Target is based on multiples of '1024'. Factors for benchmarking are [1]. Benchmarking has keying and thinking times activated. Benchmarking runs for 30 minutes.
* Experiment uses bexhoma version 0.10.4.
* System metrics are monitored by a cluster-wide installation.
* Experiment is limited to DBMS ['PostgreSQL'].
* Import is handled by 1 processes (pods).
* Loading is fixed to cl-worker19.
* Benchmarking is fixed to cl-worker19.
* SUT is fixed to cl-worker36.
* Database is persisted to disk of type shared and size 100Gi. Persistent storage is removed at experiment start.
* Loading is tested with [1] threads, split into [1] pods.
* Benchmarking is tested with [1600] threads, split into [1, 2, 5, 10] pods.
* Benchmarking is run as [1] times the number of benchmarking pods.
* Experiment is run once.
### Connections
* PostgreSQL-1-1-1-1 uses docker image postgres:18.3
* RAM:2164173213696
* CPU:INTEL(R) XEON(R) PLATINUM 8570
* Cores:224
* host:6.8.0-111-generic
* node:cl-worker36
* disk:1062821
* volume_size:100G
* volume_used:43G
* cpu_list:0-223
* args:['-c', 'max_connections=2000', '-c', 'max_worker_processes=16', '-c', 'max_parallel_workers=16', '-c', 'max_parallel_workers_per_gather=8', '-c', 'max_parallel_maintenance_workers=4', '-c', 'shared_buffers=16GB', '-c', 'effective_cache_size=40GB', '-c', 'work_mem=512MB', '-c', 'maintenance_work_mem=2GB', '-c', 'autovacuum=off', '-c', 'wal_level=minimal', '-c', 'max_wal_senders=0', '-c', 'max_wal_size=32GB', '-c', 'checkpoint_timeout=1h', '-c', 'checkpoint_completion_target=1.0', '-c', 'lock_timeout=30s', '-c', 'idle_in_transaction_session_timeout=30000']
* requests_cpu:4
* requests_memory:128Gi
* limits_memory:128Gi
* eval_parameters
* code:1783812297
* TENANT_VOL:False
* PostgreSQL-1-1-2-1 uses docker image postgres:18.3
* RAM:2164173213696
* CPU:INTEL(R) XEON(R) PLATINUM 8570
* Cores:224
* host:6.8.0-111-generic
* node:cl-worker36
* disk:1062847
* volume_size:100G
* volume_used:43G
* cpu_list:0-223
* args:['-c', 'max_connections=2000', '-c', 'max_worker_processes=16', '-c', 'max_parallel_workers=16', '-c', 'max_parallel_workers_per_gather=8', '-c', 'max_parallel_maintenance_workers=4', '-c', 'shared_buffers=16GB', '-c', 'effective_cache_size=40GB', '-c', 'work_mem=512MB', '-c', 'maintenance_work_mem=2GB', '-c', 'autovacuum=off', '-c', 'wal_level=minimal', '-c', 'max_wal_senders=0', '-c', 'max_wal_size=32GB', '-c', 'checkpoint_timeout=1h', '-c', 'checkpoint_completion_target=1.0', '-c', 'lock_timeout=30s', '-c', 'idle_in_transaction_session_timeout=30000']
* requests_cpu:4
* requests_memory:128Gi
* limits_memory:128Gi
* eval_parameters
* code:1783812297
* TENANT_VOL:False
* PostgreSQL-1-1-3-1 uses docker image postgres:18.3
* RAM:2164173213696
* CPU:INTEL(R) XEON(R) PLATINUM 8570
* Cores:224
* host:6.8.0-111-generic
* node:cl-worker36
* disk:1062856
* volume_size:100G
* volume_used:43G
* cpu_list:0-223
* args:['-c', 'max_connections=2000', '-c', 'max_worker_processes=16', '-c', 'max_parallel_workers=16', '-c', 'max_parallel_workers_per_gather=8', '-c', 'max_parallel_maintenance_workers=4', '-c', 'shared_buffers=16GB', '-c', 'effective_cache_size=40GB', '-c', 'work_mem=512MB', '-c', 'maintenance_work_mem=2GB', '-c', 'autovacuum=off', '-c', 'wal_level=minimal', '-c', 'max_wal_senders=0', '-c', 'max_wal_size=32GB', '-c', 'checkpoint_timeout=1h', '-c', 'checkpoint_completion_target=1.0', '-c', 'lock_timeout=30s', '-c', 'idle_in_transaction_session_timeout=30000']
* requests_cpu:4
* requests_memory:128Gi
* limits_memory:128Gi
* eval_parameters
* code:1783812297
* TENANT_VOL:False
* PostgreSQL-1-1-4-1 uses docker image postgres:18.3
* RAM:2164173213696
* CPU:INTEL(R) XEON(R) PLATINUM 8570
* Cores:224
* host:6.8.0-111-generic
* node:cl-worker36
* disk:1062866
* volume_size:100G
* volume_used:43G
* cpu_list:0-223
* args:['-c', 'max_connections=2000', '-c', 'max_worker_processes=16', '-c', 'max_parallel_workers=16', '-c', 'max_parallel_workers_per_gather=8', '-c', 'max_parallel_maintenance_workers=4', '-c', 'shared_buffers=16GB', '-c', 'effective_cache_size=40GB', '-c', 'work_mem=512MB', '-c', 'maintenance_work_mem=2GB', '-c', 'autovacuum=off', '-c', 'wal_level=minimal', '-c', 'max_wal_senders=0', '-c', 'max_wal_size=32GB', '-c', 'checkpoint_timeout=1h', '-c', 'checkpoint_completion_target=1.0', '-c', 'lock_timeout=30s', '-c', 'idle_in_transaction_session_timeout=30000']
* requests_cpu:4
* requests_memory:128Gi
* limits_memory:128Gi
* eval_parameters
* code:1783812297
* TENANT_VOL:False
### SUT Container Restarts
* bexhoma-sut-postgresql-1-1783812297-c86d9d9f4-8s4mb: 0 0
### Workflow
#### Actual
* DBMS PostgreSQL-1 - Experiment 1 Client 1: benchbase (1 pods)
* DBMS PostgreSQL-1 - Experiment 1 Client 2: benchbase (2 pods)
* DBMS PostgreSQL-1 - Experiment 1 Client 3: benchbase (5 pods)
* DBMS PostgreSQL-1 - Experiment 1 Client 4: benchbase (10 pods)
#### Planned
* DBMS PostgreSQL-1 - Experiment 1 Client 1: benchbase (1 pods)
* DBMS PostgreSQL-1 - Experiment 1 Client 2: benchbase (2 pods)
* DBMS PostgreSQL-1 - Experiment 1 Client 3: benchbase (5 pods)
* DBMS PostgreSQL-1 - Experiment 1 Client 4: benchbase (10 pods)
### Loading
#### Per Run
| | experiment_run | SF | time_load | time_preload | time_generate | time_ingest | time_postload | loading_pods | terminals | tenant_id | type_tenants | num_tenants | vol_tenants | Throughput [SF/h] |
|:---------------|-----------------:|-------:|------------:|---------------:|----------------:|--------------:|----------------:|---------------:|------------:|:------------|:---------------|--------------:|:--------------|--------------------:|
| PostgreSQL-1-1 | 1 | 160.00 | 4893.00 | 1.00 | 0.00 | 2183.00 | 2709.00 | 1 | 1 | | | 0 | False | 117.72 |
### Execution
#### Per Connection
| DBMS | phase | job | experiment_run | terminals | target | client | benchmark_run | child | tenant_id | time | num_errors | Throughput (requests/second) | Goodput (requests/second) | efficiency | Latency Distribution.95th Percentile Latency (microseconds) | Latency Distribution.Average Latency (microseconds) |
|:----------------------|:-----------------|:-------------------|-----------------:|------------:|---------:|---------:|----------------:|--------:|------------:|--------:|-------------:|-------------------------------:|----------------------------:|-------------:|--------------------------------------------------------------:|------------------------------------------------------:|
| PostgreSQL-1-1-1-1-1 | PostgreSQL-1-1-1 | PostgreSQL-1-1-1-1 | 1 | 1600 | 1024 | 1 | 1 | 1 | 0 | 1800.00 | 0 | 75.60 | 75.25 | 98.75 | 665032.00 | 201918.00 |
| PostgreSQL-1-1-2-1-1 | PostgreSQL-1-1-2 | PostgreSQL-1-1-2-1 | 1 | 800 | 512 | 2 | 1 | 1 | 0 | 1800.00 | 0 | 37.92 | 37.78 | 49.57 | 729907.00 | 241425.00 |
| PostgreSQL-1-1-2-1-2 | PostgreSQL-1-1-2 | PostgreSQL-1-1-2-1 | 1 | 800 | 512 | 2 | 1 | 2 | 0 | 1800.00 | 0 | 37.86 | 37.69 | 49.46 | 740845.00 | 244621.00 |
| PostgreSQL-1-1-3-1-1 | PostgreSQL-1-1-3 | PostgreSQL-1-1-3-1 | 1 | 320 | 204 | 3 | 1 | 1 | 0 | 1800.00 | 0 | 15.12 | 15.06 | 19.76 | 773592.00 | 236449.00 |
| PostgreSQL-1-1-3-1-2 | PostgreSQL-1-1-3 | PostgreSQL-1-1-3-1 | 1 | 320 | 204 | 3 | 1 | 2 | 0 | 1800.00 | 0 | 15.22 | 15.15 | 19.88 | 723871.00 | 232006.00 |
| PostgreSQL-1-1-3-1-3 | PostgreSQL-1-1-3 | PostgreSQL-1-1-3-1 | 1 | 320 | 204 | 3 | 1 | 3 | 0 | 1800.00 | 0 | 15.12 | 15.04 | 19.74 | 759177.00 | 234602.00 |
| PostgreSQL-1-1-3-1-4 | PostgreSQL-1-1-3 | PostgreSQL-1-1-3-1 | 1 | 320 | 204 | 3 | 1 | 4 | 0 | 1800.00 | 0 | 15.15 | 15.08 | 19.79 | 767241.00 | 232059.00 |
| PostgreSQL-1-1-3-1-5 | PostgreSQL-1-1-3 | PostgreSQL-1-1-3-1 | 1 | 320 | 204 | 3 | 1 | 5 | 0 | 1800.00 | 0 | 15.10 | 15.03 | 19.72 | 769635.00 | 236309.00 |
| PostgreSQL-1-1-4-1-1 | PostgreSQL-1-1-4 | PostgreSQL-1-1-4-1 | 1 | 160 | 102 | 4 | 1 | 1 | 0 | 1800.00 | 0 | 7.43 | 7.39 | 9.69 | 1491642.00 | 417386.00 |
| PostgreSQL-1-1-4-1-10 | PostgreSQL-1-1-4 | PostgreSQL-1-1-4-1 | 1 | 160 | 102 | 4 | 1 | 10 | 0 | 1800.00 | 0 | 7.65 | 7.62 | 10.00 | 1439930.00 | 417164.00 |
| PostgreSQL-1-1-4-1-2 | PostgreSQL-1-1-4 | PostgreSQL-1-1-4-1 | 1 | 160 | 102 | 4 | 1 | 2 | 0 | 1800.00 | 0 | 7.45 | 7.42 | 9.74 | 1397715.00 | 405487.00 |
| PostgreSQL-1-1-4-1-3 | PostgreSQL-1-1-4 | PostgreSQL-1-1-4-1 | 1 | 160 | 102 | 4 | 1 | 3 | 0 | 1800.00 | 0 | 7.45 | 7.41 | 9.72 | 1582314.00 | 424616.00 |
| PostgreSQL-1-1-4-1-4 | PostgreSQL-1-1-4 | PostgreSQL-1-1-4-1 | 1 | 160 | 102 | 4 | 1 | 4 | 0 | 1800.00 | 0 | 7.52 | 7.50 | 9.84 | 1356526.00 | 392942.00 |
| PostgreSQL-1-1-4-1-5 | PostgreSQL-1-1-4 | PostgreSQL-1-1-4-1 | 1 | 160 | 102 | 4 | 1 | 5 | 0 | 1800.00 | 0 | 7.50 | 7.47 | 9.81 | 1409202.00 | 410174.00 |
| PostgreSQL-1-1-4-1-6 | PostgreSQL-1-1-4 | PostgreSQL-1-1-4-1 | 1 | 160 | 102 | 4 | 1 | 6 | 0 | 1800.00 | 0 | 7.46 | 7.42 | 9.74 | 1478807.00 | 403901.00 |
| PostgreSQL-1-1-4-1-7 | PostgreSQL-1-1-4 | PostgreSQL-1-1-4-1 | 1 | 160 | 102 | 4 | 1 | 7 | 0 | 1800.00 | 0 | 7.53 | 7.50 | 9.84 | 1434196.00 | 413686.00 |
| PostgreSQL-1-1-4-1-8 | PostgreSQL-1-1-4 | PostgreSQL-1-1-4-1 | 1 | 160 | 102 | 4 | 1 | 8 | 0 | 1800.00 | 0 | 7.50 | 7.48 | 9.81 | 1538011.00 | 428255.00 |
| PostgreSQL-1-1-4-1-9 | PostgreSQL-1-1-4 | PostgreSQL-1-1-4-1 | 1 | 160 | 102 | 4 | 1 | 9 | 0 | 1800.00 | 0 | 7.48 | 7.46 | 9.79 | 1402319.00 | 418458.00 |
#### Per Phase
| DBMS | phase | experiment_run | terminals | target | benchmark_run | pod_count | tenant_id | time | num_errors | Throughput (requests/second) | Goodput (requests/second) | efficiency | Latency Distribution.95th Percentile Latency (microseconds) | Latency Distribution.Average Latency (microseconds) |
|:-----------------|:-----------------|-----------------:|------------:|---------:|----------------:|------------:|------------:|--------:|-------------:|-------------------------------:|----------------------------:|-------------:|--------------------------------------------------------------:|------------------------------------------------------:|
| PostgreSQL-1-1-1 | PostgreSQL-1-1-1 | 1 | 1600 | 1024 | 1 | 1 | 0 | 1800.00 | 0 | 75.60 | 75.25 | 98.75 | 665032.00 | 201918.00 |
| PostgreSQL-1-1-2 | PostgreSQL-1-1-2 | 1 | 1600 | 1024 | 1 | 2 | 0 | 1800.00 | 0 | 75.78 | 75.47 | 99.03 | 740845.00 | 243023.00 |
| PostgreSQL-1-1-3 | PostgreSQL-1-1-3 | 1 | 1600 | 1020 | 1 | 5 | 0 | 1800.00 | 0 | 75.70 | 75.37 | 98.90 | 773592.00 | 234285.00 |
| PostgreSQL-1-1-4 | PostgreSQL-1-1-4 | 1 | 1600 | 1020 | 1 | 10 | 0 | 1800.00 | 0 | 74.99 | 74.67 | 97.98 | 1582314.00 | 413206.90 |
### Monitoring
### Loading phase: SUT deployment
| DBMS | CPU [CPUs] | Max CPU | Max RAM [Gb] | Max RAM Cached [Gb] |
|:-------------------|-------------:|----------:|---------------:|----------------------:|
| PostgreSQL-1-1-1-1 | 1647.90 | 1.47 | 16.65 | 32.60 |
| PostgreSQL-1-1-2-1 | 1647.90 | 1.47 | 16.65 | 32.60 |
| PostgreSQL-1-1-3-1 | 1647.90 | 1.47 | 16.65 | 32.60 |
| PostgreSQL-1-1-4-1 | 1647.90 | 1.47 | 16.65 | 32.60 |
### Loading phase: component loader
| DBMS | CPU [CPUs] | Max CPU | Max RAM [Gb] | Max RAM Cached [Gb] |
|:-------------------|-------------:|----------:|---------------:|----------------------:|
| PostgreSQL-1-1-1-1 | 15221.30 | 16.51 | 0.30 | 0.30 |
| PostgreSQL-1-1-2-1 | 15221.30 | 16.51 | 0.30 | 0.30 |
| PostgreSQL-1-1-3-1 | 15221.30 | 16.51 | 0.30 | 0.30 |
| PostgreSQL-1-1-4-1 | 15221.30 | 16.51 | 0.30 | 0.30 |
### Execution phase: SUT deployment
| DBMS | CPU [CPUs] | Max CPU | Max RAM [Gb] | Max RAM Cached [Gb] |
|:-------------------|-------------:|----------:|---------------:|----------------------:|
| PostgreSQL-1-1-1-1 | 405.90 | 3.71 | 26.08 | 42.35 |
| PostgreSQL-1-1-2-1 | 299.29 | 0.32 | 26.14 | 42.63 |
| PostgreSQL-1-1-3-1 | 317.28 | 0.49 | 26.85 | 43.53 |
| PostgreSQL-1-1-4-1 | 325.55 | 0.52 | 27.46 | 44.32 |
### Execution phase: component benchmarker
| DBMS | CPU [CPUs] | Max CPU | Max RAM [Gb] | Max RAM Cached [Gb] |
|:-------------------|-------------:|----------:|---------------:|----------------------:|
| PostgreSQL-1-1-1-1 | 410.50 | 1.58 | 4.16 | 4.16 |
| PostgreSQL-1-1-2-1 | 410.50 | 2.34 | 3.98 | 3.98 |
| PostgreSQL-1-1-3-1 | 504.05 | 4.95 | 2.35 | 2.35 |
| PostgreSQL-1-1-4-1 | 752.63 | 9.90 | 1.06 | 1.06 |
### Tests
* TEST passed: No SUT container restarts
* TEST passed: Loading phase: SUT deployment contains no 0 or NaN in CPU [CPUs]
* TEST passed: Loading phase: component loader contains no 0 or NaN in CPU [CPUs]
* TEST passed: Execution phase: SUT deployment contains no 0 or NaN in CPU [CPUs]
* TEST passed: Execution phase: component benchmarker contains no 0 or NaN in CPU [CPUs]
* TEST passed: Throughput (requests/second) contains no 0 or NaN
* TEST passed: Workflow as planned
Now also efficiency is computed via 0.45 * 60. * 100. * Goodput (requests/second) / 12.86 / sf, when number of client threads is 10 times the number of warehouses:
45% is the average portion of new orders in the set of transactions
60 transforms to per-minute
100 makes it a percentage value
Goodput (requests/second) is the number of successful transactions per second
sf is the number of warehouses
12.86 is the theoretical limit in the TPC-C speficications
Note that these are statistical values.